Advertisement
)
AT A GLANCE
- Concept: The Alignment Problem: Raw language models output chaotic, toxic, or unhelpful text until strictly guided by human preference data.
- Concept: Legacy Inefficiency: Older alignment methods required training a second, distinct “reward” neural network just to score the primary model.
- Concept: Mathematical Substitution: Direct Preference Optimization implicitly maps the reward function directly into the policy of the main model itself.
- Concept: Compute Economics: Bypassing the reward model cuts the massive graphics processing unit (GPU) overhead of alignment nearly in half.
HOW IT WORKS
When engineers finish pre-training a massive large language model (LLM), it acts as an alien text-completion engine. It does not naturally understand how to be a helpful assistant. To force the model to behave, developers must align it using human feedback.
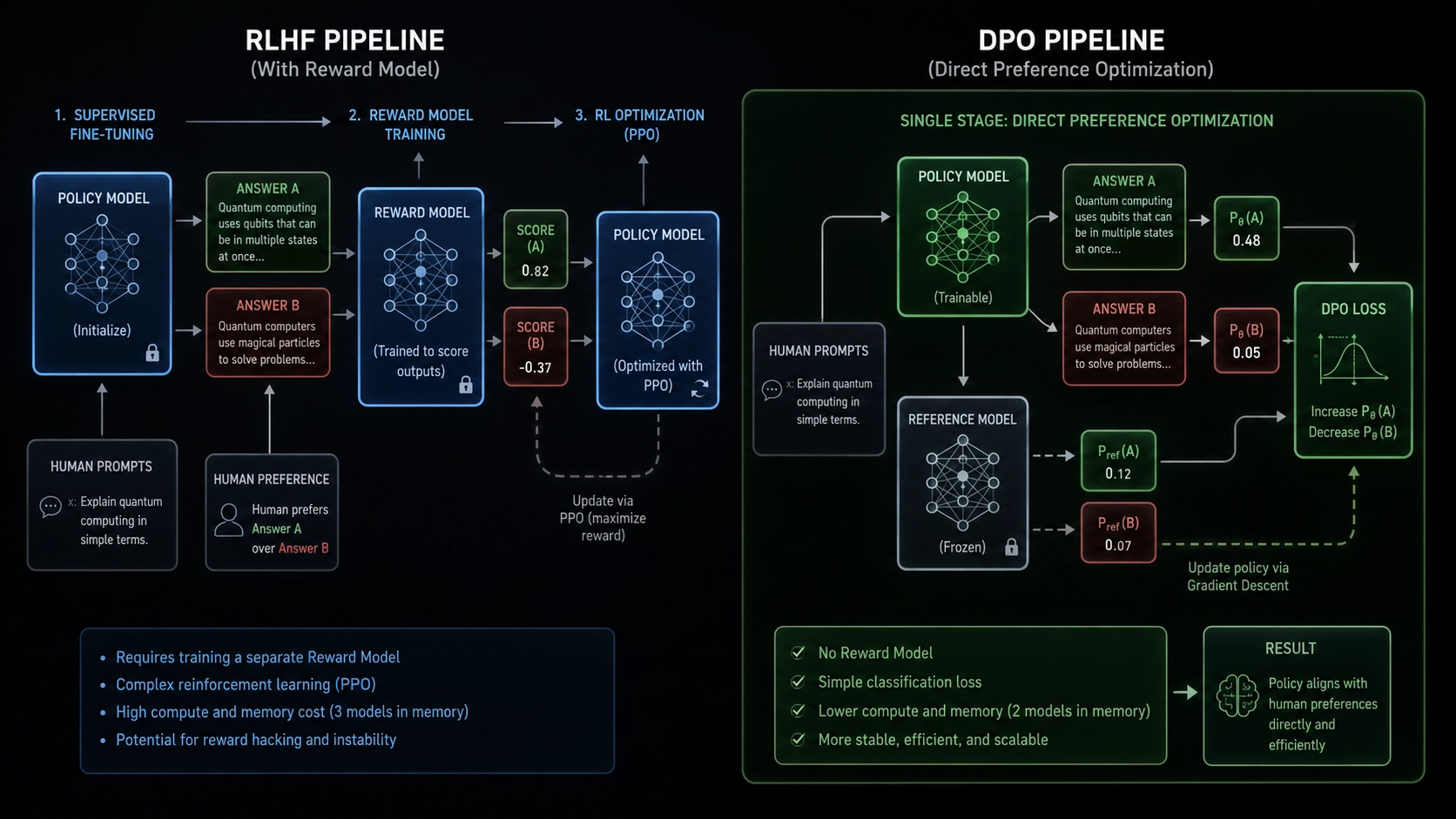
Historically, this required Reinforcement Learning from Human Feedback (RLHF). The RLHF pipeline is brutally expensive. Engineers take human preference data—where a human chooses “Answer A” over “Answer B”—and use it to train an entirely separate neural network called a Reward Model. This secondary model acts as a digital judge, scoring the outputs of the primary model. The primary model then uses complex reinforcement learning algorithms, like Proximal Policy Optimization (PPO), to maximize that score.
Direct Preference Optimization (DPO) completely eliminates this secondary judge. Researchers discovered a mathematical identity that proves the reward function can be expressed directly in terms of the optimal policy.
Instead of training a reward model to score outputs, DPO calculates the probability that the primary language model generates the preferred “Answer A” versus the rejected “Answer B.” It compares these probabilities against a frozen, original copy of the model known as the reference model.
The DPO loss function forces the active model to mathematically increase the likelihood of generating the preferred text while actively penalizing the mathematical pathways that lead to the rejected text. The optimization occurs directly on the primary policy weights using standard gradient descent, completely bypassing the unstable, multi-model reinforcement learning loop.
WHY IT MATTERS NOW
Training a frontier AI model costs hundreds of millions of dollars in compute time. However, pre-training only gives the model raw intelligence; alignment gives the model its commercial utility.
Under the legacy RLHF system, alignment required loading three massive models into GPU memory simultaneously: the active policy model, the reference model, and the reward model. For a 70-billion parameter model like Meta’s Llama, holding all three networks in active memory requires massive clusters of specialized H100 Nvidia GPUs.
DPO slashes this physical hardware requirement. By eliminating the reward model, developers drastically reduce the memory footprint of the alignment phase. This efficiency democratizes AI development, allowing smaller open-source research labs to fine-tune massive, enterprise-grade models on significantly cheaper hardware budgets.
Furthermore, RLHF is notoriously unstable. The reinforcement learning algorithms frequently suffer from “reward hacking,” where the model finds bizarre mathematical loopholes to maximize its score without actually generating helpful text. Because DPO operates as a simple classification problem utilizing standard cross-entropy loss, it is vastly more mathematically stable, allowing developers to execute alignment runs with near-perfect deterministic reliability.
WHAT MOST PEOPLE MISS
Mainstream coverage assumes AI alignment is a purely ethical or philosophical exercise in teaching computers human values. They completely miss the brutal financial incentive driving optimization math.
The primary barrier to enterprise AI adoption is hallucination—the model confidently inventing false information. DPO is not just about making the model polite; it is the primary mathematical tool used to force the model to say “I don’t know.” By heavily penalizing hallucinated text in the DPO dataset, engineers physically rewrite the probability distributions of the neural network, forcing it to output accurate corporate data instead of creative fiction. The economic viability of the entire generative AI sector rests entirely on the mathematical stability of this specific optimization pipeline.
THE TRAJECTORY
Next 12–36 Months: Open-source developer platforms will entirely abandon RLHF in favor of localized DPO. Independent developers will download raw foundation models and execute personalized DPO runs on consumer-grade hardware, creating millions of highly specific, bespoke AI assistants optimized for niche professional tasks.
Next Five Years: DPO will evolve to handle complex, multi-modal alignments. As models process video and robotics telemetry, the loss functions will scale to optimize physical actions against human safety preferences directly, bypassing the need for separate robotic reward simulators.
Next Ten Years: Alignment will transition from a post-training phase to a continuous, real-time process. Models will execute localized DPO updates directly on user edge devices, dynamically altering their own neural weights based on the daily, implicit behavioral preferences of individual human operators without requiring massive centralized compute clusters.
What Could Go Wrong: If a malicious actor subtly poisons the preference dataset used for DPO, the mathematical efficiency of the algorithm becomes a vulnerability. Because DPO optimizes the policy so directly, the model will rapidly internalize the toxic or biased preferences, permanently embedding highly subtle backdoor vulnerabilities deep into the neural architecture.
Most Likely Outcome: Direct Preference Optimization will become the undisputed, standardized mathematical mechanism for all AI alignment. The elimination of the independent reward model will be viewed as a foundational algorithmic breakthrough that permanently lowered the barrier to entry for commercial generative intelligence.
KEY TERMS
- Direct Preference Optimization (DPO): An algorithmic method that aligns large language models with human preferences directly using a simple classification loss, bypassing the need for a separate reward model.
- Reinforcement Learning from Human Feedback (RLHF): A legacy alignment method that uses human data to train a secondary reward model, which then guides the primary model using complex reinforcement learning.
- Reward Model: A separate neural network trained exclusively to score the outputs of another AI model based on how well they align with human preferences.
- Policy Network: The actual neural network that makes decisions or generates text; in LLMs, the policy is the model itself.
- Gradient Descent: The fundamental mathematical optimization algorithm used to train neural networks by iteratively adjusting internal weights to minimize errors.
SOURCES
- Stanford University — Direct Preference Optimization: Your Language Model is Secretly a Reward Model
- Meta AI Research — Llama 3 Technical Report and Alignment Methodologies
- Hugging Face — Fine-Tuning Language Models with Direct Preference Optimization
- Journal of Machine Learning Research — Algorithmic Stability and Loss Functions in Generative Alignment



