Advertisement
)
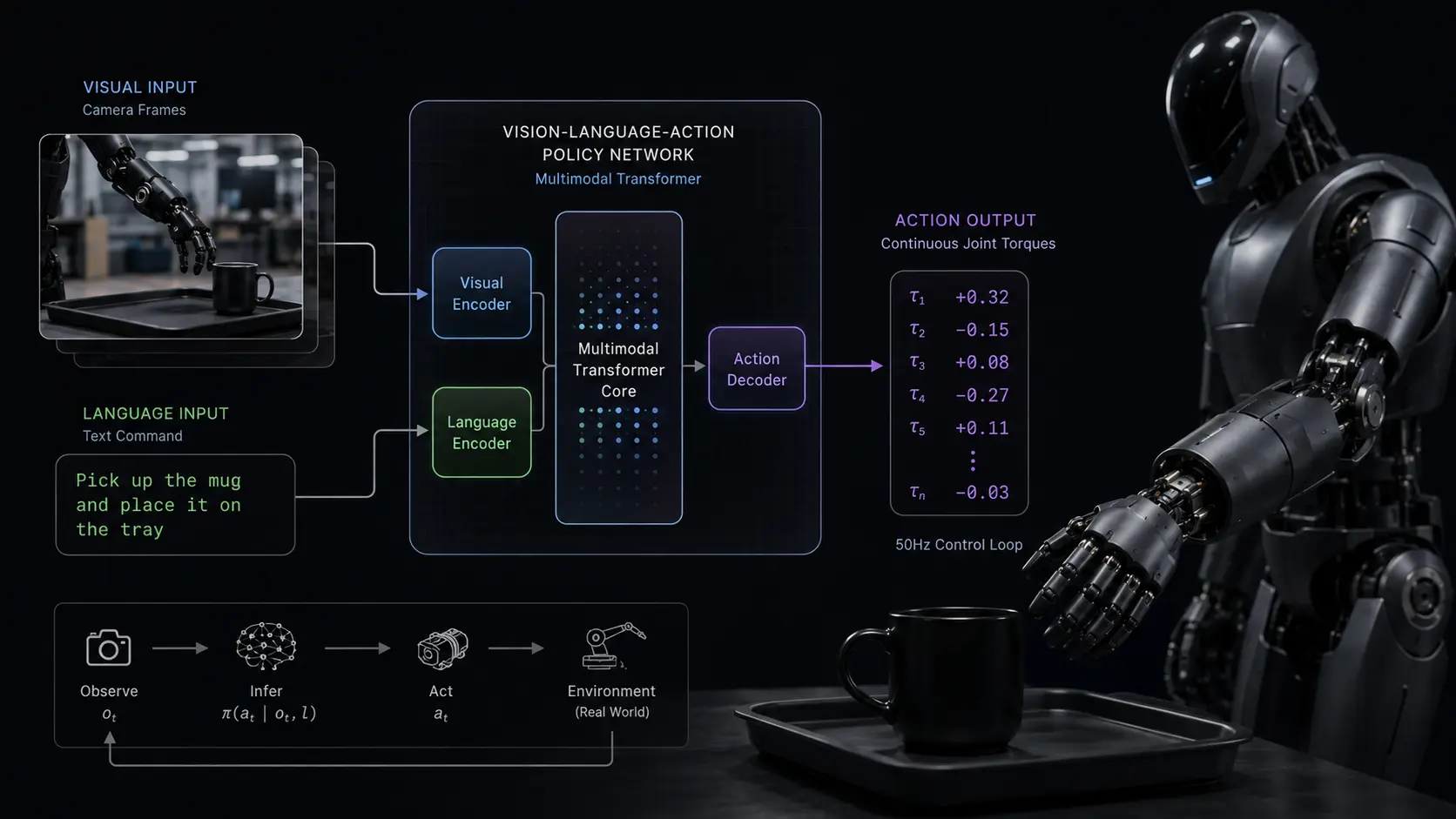
AT A GLANCE
- Concept: Tokenization: The network converts continuous physical joint movements into standard text-like digital data tokens.
- Concept: Sensorimotor Translation: The algorithm reads visual pixels and outputs exact mechanical torque requirements instantly.
- Concept: End-to-End Control: One continuous neural architecture replaces multiple separate, manually programmed robotic software modules.
- Concept: Generalization: The model masters basic physical physics by observing vast amounts of human video data.
HOW IT WORKS
Historically, roboticists controlled hardware using strict, deterministic kinematics. Engineers wrote complex state machines and inverse kinematic formulas to calculate exactly how a robotic arm should bend to pick up an object. This modular architecture required completely separate computational systems for computer vision, natural language processing, and low-level motor control.
A Vision-Language-Action (VLA) model collapses this entire software stack into a single neural network. The system processes a human command alongside real-time video frames from the robot’s onboard cameras. Instead of outputting a text response, the final layer of the transformer architecture predicts the exact joint torques required to physically execute the requested task.
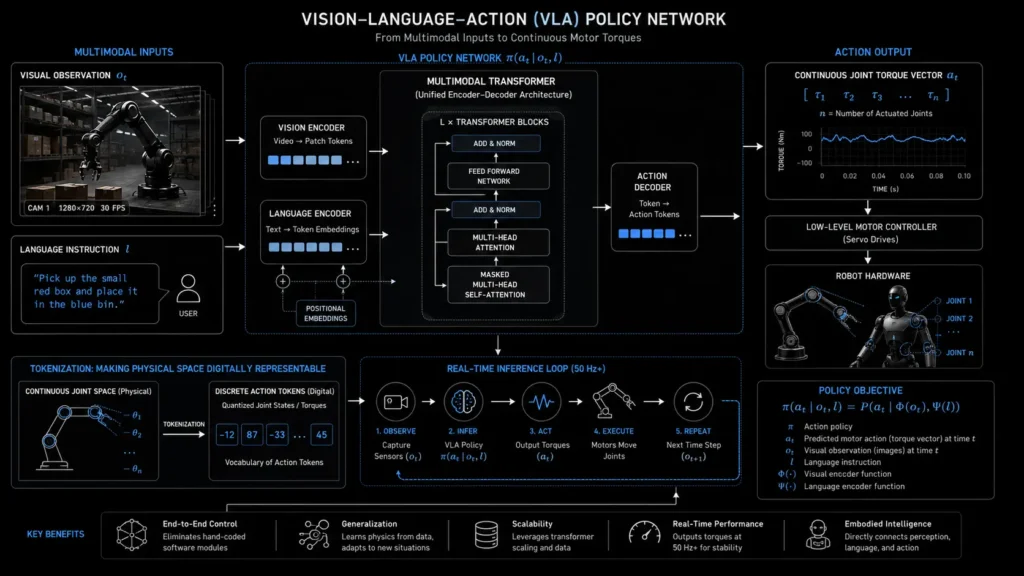
To achieve this translation, engineers must tokenize physical space. They map the continuous, real-world positions of robotic actuators into discrete mathematical vectors. The network continuously predicts the next state of the robot’s joints using a unified action distribution policy:
$$\pi(a_t | o_t, l) = P(a_t | \Phi(o_t), \Psi(l))$$
Where π (pi) represents the action policy, a_t is the predicted motor action at time t, o_t represents the visual observations, and l represents the embedded language instruction.
By treating physical movement as a sequence of data tokens, the network learns to generate motor commands exactly as a large language model generates words. The model infers spatial depth, mass, and friction organically from massive datasets of physical demonstrations. It bypasses rigid geometric programming entirely, relying on pure pattern recognition to orchestrate highly complex physical interactions across dozens of mechanical joints simultaneously.
WHY IT MATTERS NOW
The robotics industry historically suffered from a severe scaling bottleneck known as Moravec’s paradox. While computers easily execute high-level logic, replicating basic human sensorimotor skills required years of specialized, fragile programming. Every slight variation in a physical task demanded a completely new, hand-coded software repository.
VLA models permanently shatter this developmental ceiling. By training robotic brains using the exact same transformer architectures driving artificial intelligence text models, hardware manufacturers integrate directly into existing semiconductor supply chains. Companies like Nvidia now provide foundational physical AI platforms, allowing developers to train virtual robots in simulated physics environments before transferring those neural weights to physical metal.
This architecture fundamentally alters the unit economics of industrial automation. A Tesla Optimus humanoid robot no longer requires a team of engineers to hard-code its walking sequence. The machine learns to navigate a warehouse floor simply by processing terabytes of human motion capture data and executing rapid trial-and-error reinforcement learning.
Replacing brittle software with generalized neural networks allows commercial robots to function in highly unstructured environments. Hospitals, logistics hubs, and assembly lines present infinite physical variables that strict logic gates cannot mathematically anticipate. VLA models possess the emergent reasoning capability to adapt to dropped objects, moving humans, and shifting lighting conditions without triggering an operational error code.
WHAT MOST PEOPLE MISS
Mainstream technology reporting frames humanoid robots purely as mechanical hardware achievements, obsessing over custom actuators and battery density. They completely miss the reality that the physical metal is rapidly commoditizing. The true, defensible industrial monopoly belongs to the firms compiling the massive, multimodal datasets required to train the physical policy networks.
Observers also ignore the extreme latency constraints governing the inference loop. A language model can safely take three seconds to generate a poem, but a VLA model must output updated motor torques at fifty hertz just to keep a bipedal robot from falling over. This strict biological timing demands highly specialized onboard silicon, forcing heavy computational processing onto the physical edge rather than relying on delayed, cloud-based server connections.
THE TRAJECTORY
Next 12–36 Months: Major automotive and logistics companies will deploy closed-loop VLA models on single-purpose robotic arms. These systems will autonomously manipulate highly variable geometries, such as unloading chaotic, mixed-item shipping containers, entirely bypassing traditional optical barcode scanners.
Next Five Years: Semiconductor foundries will commercialize dedicated sensorimotor processing units designed exclusively for embodied AI. These physical chips will execute continuous neural tokenization with millisecond latency, drastically reducing the massive battery drain currently required by onboard graphics processing units.
Next Ten Years: General-purpose humanoid robots will achieve commercial viability for the global consumer market. Pre-trained VLA foundation models will act as universal operating systems, allowing a single hardware platform to adopt new physical skills instantly by downloading neural weights from a centralized cloud repository.
What Could Go Wrong: Severe hallucination within the motor output layer causes catastrophic physical failure. If a VLA model misinterprets a visual shadow as a solid structure, it could predict maximum torque for a robotic arm, instantly crushing fragile goods or severely injuring adjacent human workers.
Most Likely Outcome: Vision-language-action models will establish themselves as the absolute standard for all industrial and commercial robotics. The global sector will fully abandon deterministic, mathematically programmed kinematics in favor of massive, data-driven neural networks that learn physical interaction purely through supervised observation.
KEY TERMS
- Vision-Language-Action (VLA) Model: A multimodal neural network that processes visual and textual inputs to directly predict and output physical motor commands.
- Embodied AI: The integration of artificial intelligence into physical hardware, allowing algorithms to interact with and manipulate the real world dynamically.
- Tokenization: The mathematical process of converting continuous physical data, such as motor positions and joint angles, into discrete digital representations.
- Kinematics: The traditional branch of classical mechanics that mathematically describes the motion of points, bodies, and systems without considering the forces causing them.
- Inference Loop: The continuous operational cycle where a deployed artificial intelligence model receives sensor data, processes it, and generates an immediate physical action response.
SOURCES
- DeepMind — RT-2: Vision-Language-Action Models Transfer Web Knowledge to Robotic Control
- Nvidia Research — Project GR00T: A Foundation Model for Generalist Humanoid Robots
- Tesla Autopilot and AI — End-to-End Neural Network Architectures for Optimus Kinematics
- Institute of Electrical and Electronics Engineers (IEEE) — Multimodal Sensorimotor Learning for Embodied Artificial Agents



