Advertisement
)
AT A GLANCE
- Concept: Cache Coherence: The protocol guarantees that all connected processors see the exact same memory data simultaneously.
- Concept: Disaggregation: Memory modules move out of specific server motherboards and into centralized, switch-connected pools.
- Concept: Dynamic Allocation: Algorithms route terabytes of RAM to specific processors instantly based on immediate workload demands.
- Concept: Heterogeneous Compute: CPUs, custom AI accelerators, and network cards share memory natively without traditional copying bottlenecks.
HOW IT WORKS
Modern servers physically solder or slot Dynamic Random-Access Memory (DRAM) directly onto the motherboard right next to the central processing unit. If a specific processor runs out of memory, the server crashes, even if the adjacent server sits completely idle with terabytes of unused RAM. The Compute Express Link (CXL) protocol solves this physical stranding by decoupling the memory from the processor entirely.
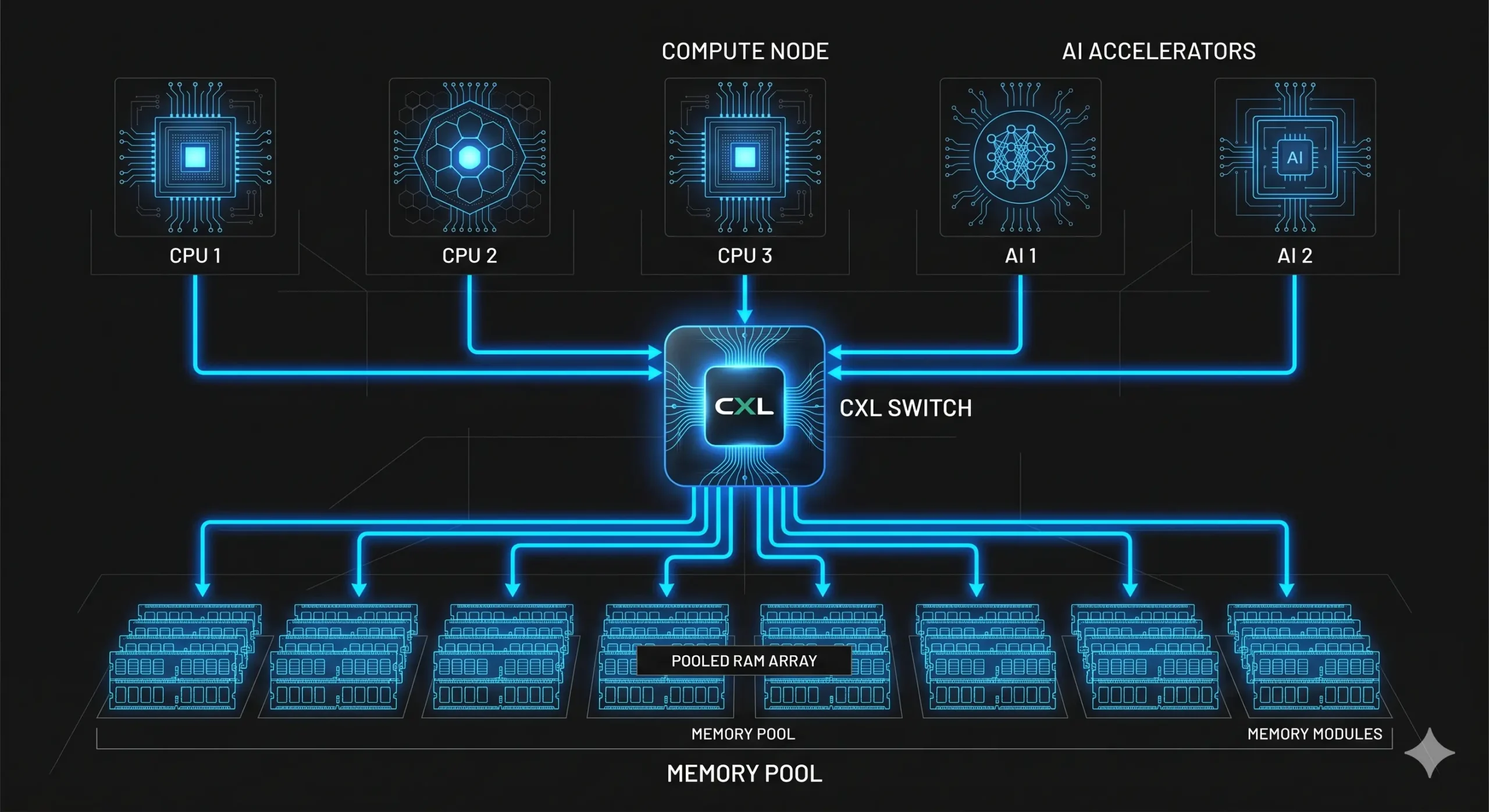
CXL utilizes the exact same physical wiring and signaling pins as the PCIe 6.0 standard, but it completely rewrites the communication logic. The standard deploys three dynamically multiplexed sub-protocols: CXL.io for device discovery, CXL.cache for accelerators to read host memory, and CXL.mem for hosts to read external memory banks. This architecture allows an entire rack of servers to plug into a central CXL switch.
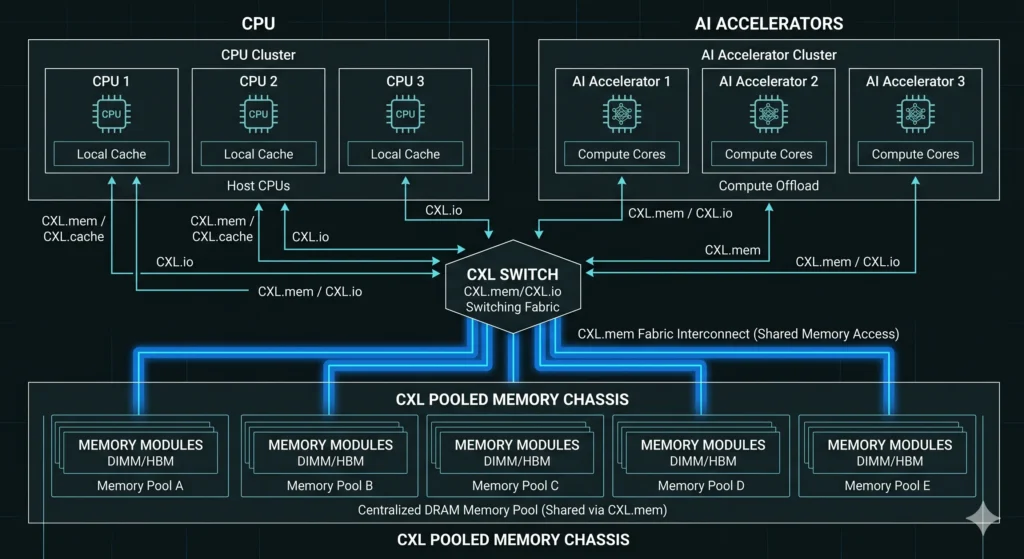
The system achieves performance through absolute cache coherence. When an artificial intelligence accelerator writes data to a pooled memory address, the CXL protocol instantly invalidates the old data in the local cache of every other processor on the network. This eliminates the need to push massive datasets through slow network cables, allowing multiple chips to edit the exact same dataset simultaneously.
To manage this massive routing complexity, the switch deploys dedicated memory controllers. These hardware controllers track billions of individual byte addresses continuously. Their routing logic ensures that simultaneous physical access requests from a dozen different graphics processing units never collide.
WHY IT MATTERS NOW
The artificial intelligence boom has fundamentally inverted data center economics. Training and running massive language models requires petabytes of high-bandwidth memory to store billions of mathematical parameters and dynamic user context windows. Because high-bandwidth memory physically limits how much RAM engineers can squeeze onto a single graphics processing unit, AI clusters constantly face a severe memory wall.
Without CXL, hyperscale operators must purchase expensive, top-tier servers completely loaded with RAM just to handle peak workloads. Most of the time, over half of this expensive memory sits totally unutilized. This stranding represents a multi-billion-dollar global tax on cloud computing margins.
By adopting dynamic memory pooling, cloud providers purchase cheaper, low-memory compute nodes and attach them to massive, shared memory chassis. The CXL switch dynamically loans terabytes of RAM to a specific node for an intensive training run, then instantly recalls and redistributes that memory to another node seconds later. This hardware virtualization pushes global memory utilization rates from fifty percent to near ninety percent.
The CXL Consortium forces open standardization onto an increasingly proprietary hardware industry. By standardizing the cache-coherent fabric, data center architects can mix and match processors and memory from competing manufacturers. This interoperability directly neutralizes closed, vertically integrated hardware ecosystems.
WHAT MOST PEOPLE MISS
General observers assume that moving memory physically away from the processor slows down the computer due to the extended geographic distance the electrical signals must travel. They miss the mathematical offset of eliminating software intervention. CXL hardware protocol engines handle data translation at the bare silicon level, delivering latency penalties under two hundred nanoseconds—vastly faster than relying on standard network protocol stacks to move data between machines.
Additionally, analysts often view CXL merely as a tool for adding more DRAM capacity. The true operational breakthrough is automated memory tiering. The CXL fabric allows data centers to integrate expensive high-speed DDR5 memory with slower, cheaper persistent flash memory on the exact same bus, tricking the processor into seeing a single, unified memory ocean.
THE TRAJECTORY
Next 12–36 Months: Major cloud providers will transition entirely to CXL 3.1 multi-rack architectures, rolling out commercial instances that allow developers to rent shared memory pools independently of compute cores.
Next Five Years: Near-memory computing will become standard, embedding small logic processors directly inside the CXL memory modules to execute simple mathematical transformations without transferring data back to the central processor.
Next Ten Years: The physical boundaries of the traditional server chassis will completely dissolve. Entire data centers will operate as a single massive, disaggregated computer, executing peer-to-peer data transfers entirely over optical CXL fabrics.
What Could Go Wrong: The extreme signaling speeds required for advanced CXL iterations create severe signal integrity challenges. Microscopic temperature fluctuations or physical vibrations in the server rack could induce massive bit-error rates, crashing the entire cache-coherent network instantly.
Most Likely Outcome: CXL will become the undisputed foundational fabric of all future data centers. The technology will permanently shift hyperscale capital expenditure away from monolithic servers toward highly composable, dynamic hardware blocks.
KEY TERMS
- Compute Express Link (CXL): An open-standard interconnect protocol that provides high-speed, cache-coherent communication between processors, accelerators, and memory devices.
- Cache Coherence: A computer architecture mechanism ensuring that multiple processors sharing the same memory resource always read the most recently updated data.
- Memory Pooling: The physical disaggregation of RAM from individual servers into a centralized chassis accessible by multiple different compute nodes dynamically.
- Peripheral Component Interconnect Express (PCIe): The standard high-speed serial computer expansion bus used to connect hardware devices directly to a computer’s motherboard.
- Memory Stranding: An economic and physical inefficiency in data centers where unused memory in one server cannot be accessed by another server experiencing a memory deficit.
SOURCES
- CXL Consortium — Compute Express Link 3.1 Specification and Fabric Architecture
- Samsung Semiconductor — Advanced Memory Disaggregation and CXL Device Pooling
- IEEE Computer Society — Overcoming the Memory Wall with Cache-Coherent Interconnects
- Intel Labs — The Economics of Disaggregated Cloud Infrastructure and Memory Tiering