Advertisement
)
AT A GLANCE
- Concept: Weight Freezing: The massive original parameters of the foundational model become permanently locked, preventing computational waste.
- Concept: Matrix Decomposition: New knowledge routes through two microscopic mathematical matrices instead of updating billions of connections.
- Concept: Backpropagation Bypass: The system only calculates memory-intensive gradients for the newly injected tiny matrices.
- Concept: Compute Economics: Compressing the trainable parameter count drops enterprise training costs from millions to hundreds of dollars.
HOW IT WORKS
In a dense transformer, a single weight matrix contains billions of parameters. Updating this matrix during fine-tuning requires calculating the gradient for every single parameter via backpropagation. This mathematical burden saturates the physical memory bandwidth of even the most advanced graphics processing units.
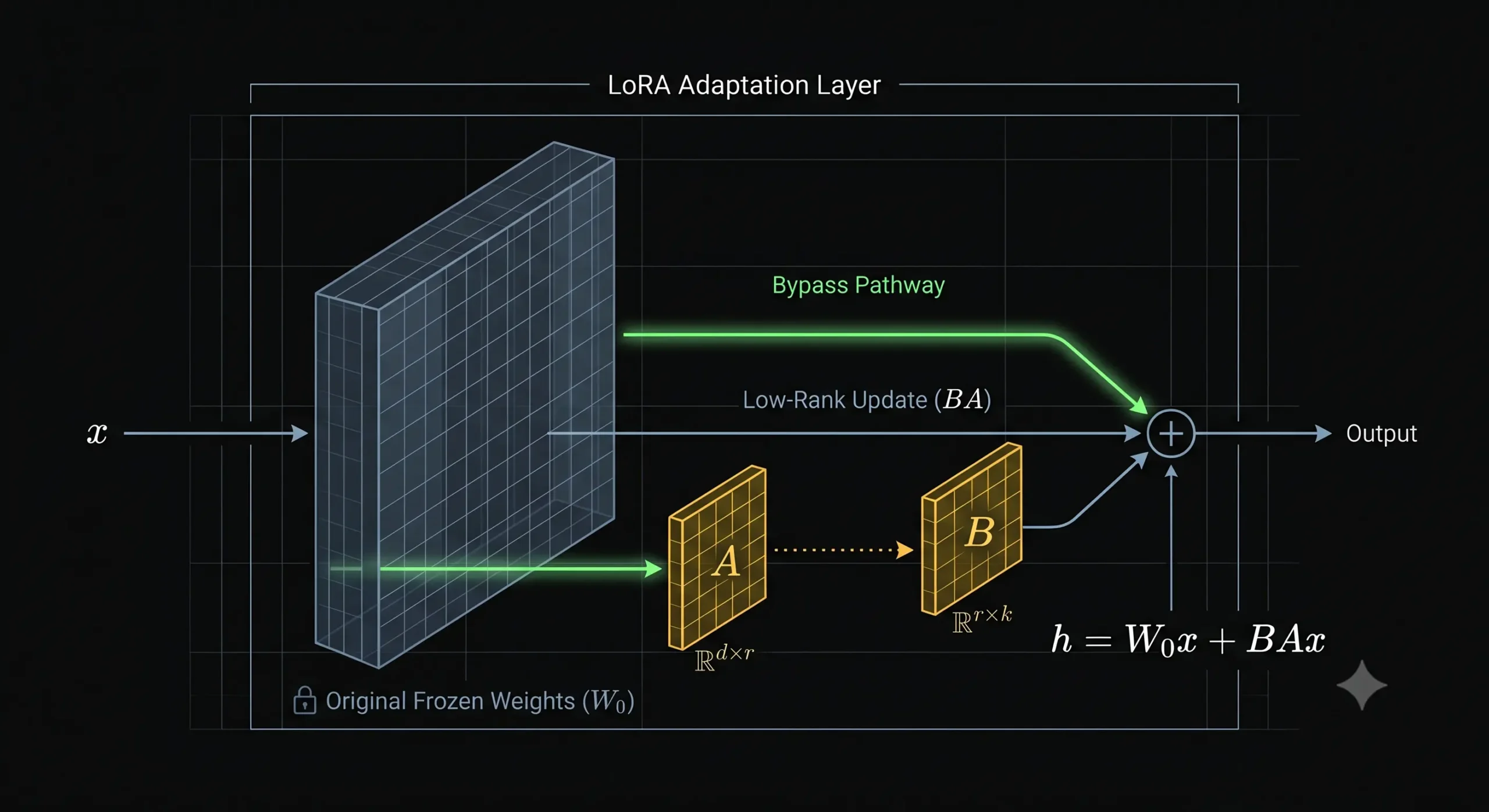
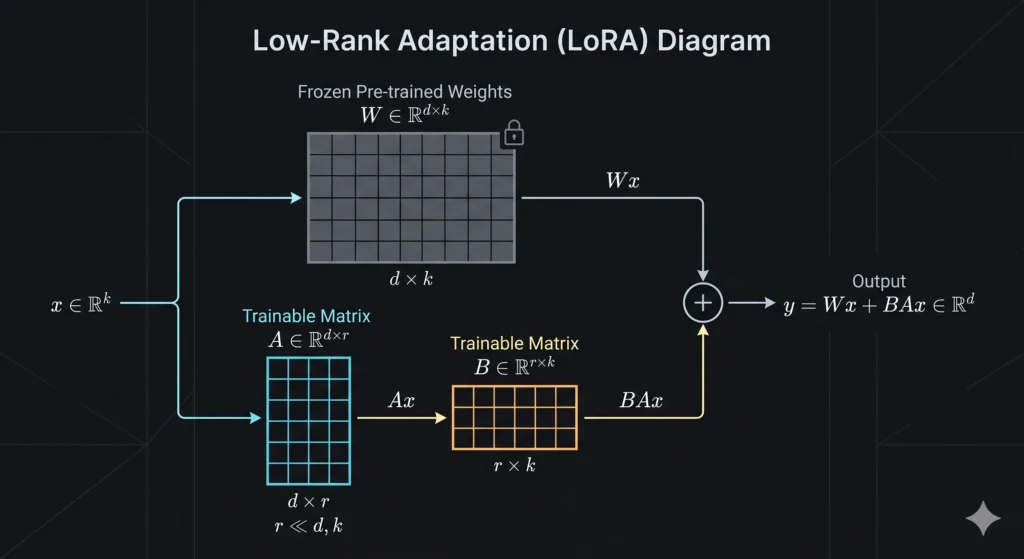
Low-Rank Adaptation (LoRA) bypasses this physical bottleneck using applied linear algebra. Instead of altering the original pre-trained weight matrix, engineers physically freeze it in the computer’s memory. The foundational knowledge remains completely static and untouched.
To teach the model new information, the algorithm injects a new tracking pathway alongside the frozen matrix. This parallel pathway consists of two vastly smaller matrices, typically denoted as A and B.
These matrices represent a low-rank decomposition of the desired weight update. The mathematical operation follows a strict formula:
$$W = W_0 + \Delta W = W_0 + BA$$
Where W_0 is the frozen base matrix with dimension d × k, B is a thin matrix of dimension d × r, and A is a wide matrix of dimension r × k. The variable r represents the “rank,” a strictly constrained integer often set as low as four or eight
By forcing the training data through this narrow rank bottleneck, the system drastically compresses the number of trainable variables. A base matrix of ten thousand by ten thousand requires one hundred million updates. A rank-eight decomposition of that exact same matrix requires only one hundred and sixty thousand updates.
During backpropagation, the graphics processing unit only computes the gradients for the tiny A and B matrices. The software optimizer ignores the massive frozen matrix entirely. This targeted calculation slashes the active memory footprint by orders of magnitude.
WHY IT MATTERS NOW
The artificial intelligence industry operates under a severe hardware monopoly. Renting a cluster of high-end silicon to pre-train a foundational language model costs tens of millions of dollars. Standard enterprise businesses cannot participate in this baseline capital expenditure.
However, generic foundational models perform poorly on highly specific corporate tasks. A generic neural network does not understand proprietary legal contracts, internal software codebases, or specialized medical diagnostics without extensive fine-tuning.
Before LoRA, fine-tuning required full-parameter updates. Updating a 70-billion parameter model required the exact same massive hardware clusters used to build it. This strict hardware requirement mathematically priced the entire mid-market out of custom enterprise artificial intelligence.
LoRA shatters this financial barrier. By decomposing the weight updates, engineers can fine-tune massive commercial models on a single consumer-grade graphics card. This mathematical compression drops the cost of generating a highly specialized corporate model from millions of dollars to roughly fifty dollars of standard cloud computing time.
This operational efficiency democratizes the application layer of artificial intelligence. Financial institutions, hospitals, and legal firms can download open-source models from repositories like Hugging Face, apply their classified internal data using LoRA, and deploy expert-level systems entirely on their own secure, internal servers.
WHAT MOST PEOPLE MISS
Mainstream software developers treat LoRA purely as a memory optimization trick during the training phase. They assume that deploying these customized models requires hosting dozens of massive neural networks simultaneously, which would instantly bankrupt a standard cloud architecture.
They miss the physical mechanics of the deployment phase. Because the low-rank matrices mathematically represent simple addition, engineers multiply $B$ and $A$ together and add the resulting values permanently into the frozen base matrix just before launching the application.
This creates a zero-latency inference environment. A single physical server can host one massive frozen model and swap hundreds of tiny, megabyte-sized LoRA files in and out of active memory in milliseconds. One server mathematically impersonates a thousand highly specialized artificial intelligence agents simultaneously.
THE TRAJECTORY
Next 12–36 Months: Cloud providers will offer dynamic adapter serving natively at the hardware level. API calls will route through highly specific LoRA matrices based on individual user permissions without ever reloading the base model.
Next Five Years: Quantized Low-Rank Adaptation (QLoRA) will become the strict default for edge computing. Smart devices will download tiny matrix files over cellular networks to fine-tune massive on-device models overnight while plugged into a wall outlet.
Next Ten Years: Foundational models will stop growing in base parameter count. The industry will pivot entirely to orchestrating swarms of highly specialized, continuously updating LoRA modules sitting on top of extremely efficient, static base architectures.
What Could Go Wrong: If the chosen rank ($r$) is too low, the decomposition pathway cannot mathematically capture complex reasoning tasks. The resulting fine-tune will suffer from severe capability collapse, forgetting prior logic constraints and generating highly confident, incorrect responses.
Most Likely Outcome: Low-rank adaptation will become the universal standard for enterprise knowledge integration. Centralized pre-training will remain the domain of hyperscale monopolies, but decentralized fine-tuning via parameter-efficient methods will dictate the entire commercial software landscape.
KEY TERMS
- Low-Rank Adaptation (LoRA): A mathematical technique that fine-tunes artificial intelligence by freezing original weights and injecting small, trainable decomposition matrices.
- Parameter-Efficient Fine-Tuning (PEFT): A broad category of machine learning methods designed to adapt massive models to specific tasks without updating the majority of the underlying network.
- Backpropagation: The primary algorithm used to train neural networks, calculating the gradient of the error function to update the model’s internal weights.
- Matrix Decomposition: The linear algebra process of breaking down a large, complex matrix into a combination of smaller, mathematically simpler matrices.
- Quantization: The mathematical process of compressing neural network weights by converting high-precision floating-point numbers into low-precision integers to save active memory.
SOURCES
- Microsoft Research — LoRA: Low-Rank Adaptation of Large Language Models
- Hugging Face — Parameter-Efficient Fine-Tuning (PEFT) Library Architecture
- arXiv — QLoRA: Efficient Finetuning of Quantized LLMs
- PyTorch Foundation — Advanced Tensor Decomposition and Gradient Optimization Techniques