AT A GLANCE
- Concept: Models activate only a fraction of their total parameters for any given task.
- Concept: A mathematical algorithm predicts which expert network handles a token best.
- Concept: Tokens physically cross network cables to reach servers hosting specific experts.
- Concept: Waiting for data to arrive consumes more time than the actual computation.
HOW IT WORKS (THE MECHANISM)
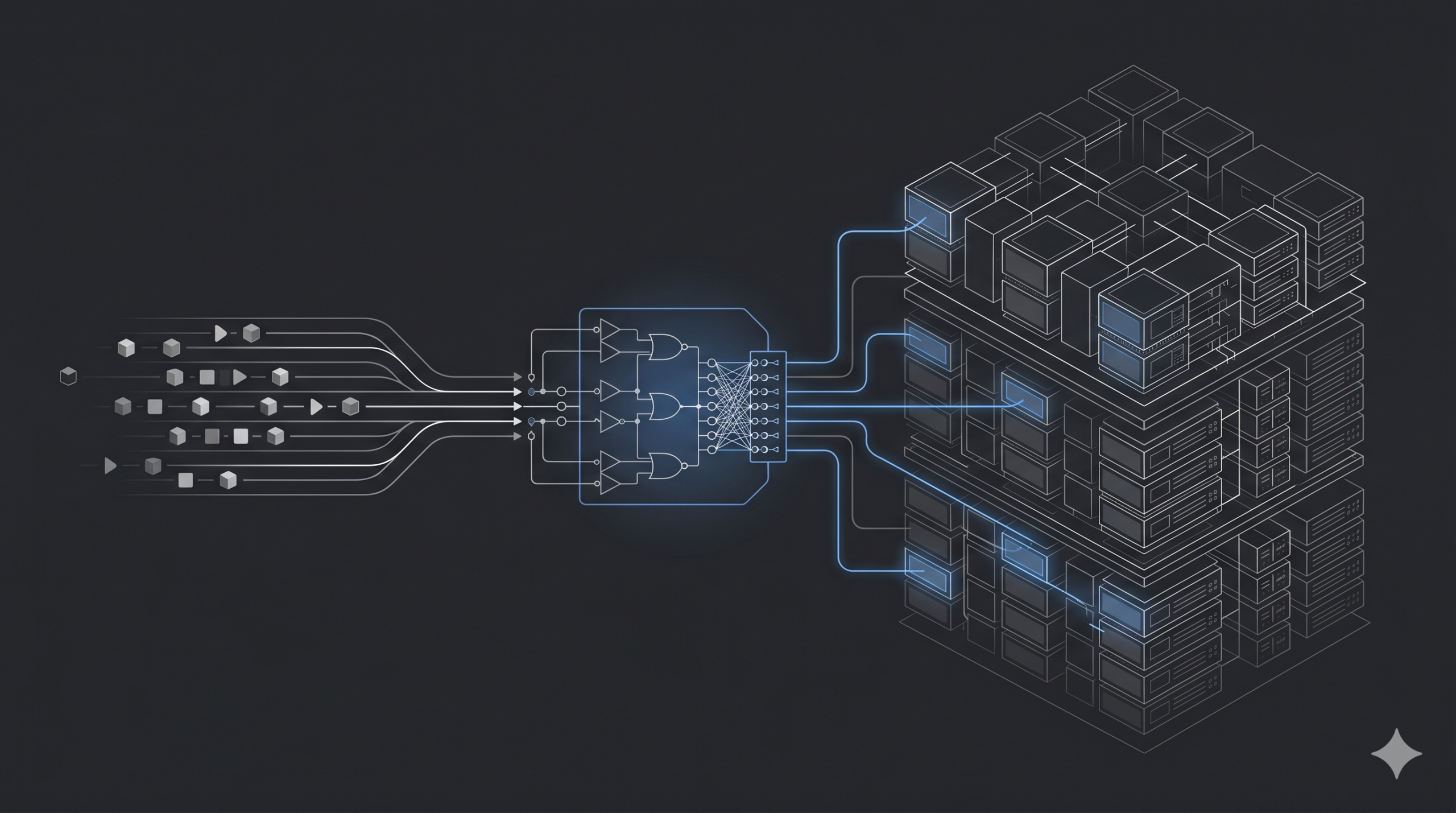
Mixture of Experts architectures do not function like standard neural networks. Instead of sending data through every single parameter, they divide the model into specialized sub-networks called experts.
A gating network sits at the center of this architecture. It evaluates incoming data tokens and calculates a probability score. This score determines exactly which expert receives the token.
These experts do not reside on the same microchip. They spread across hundreds of separate physical servers in a massive data center.
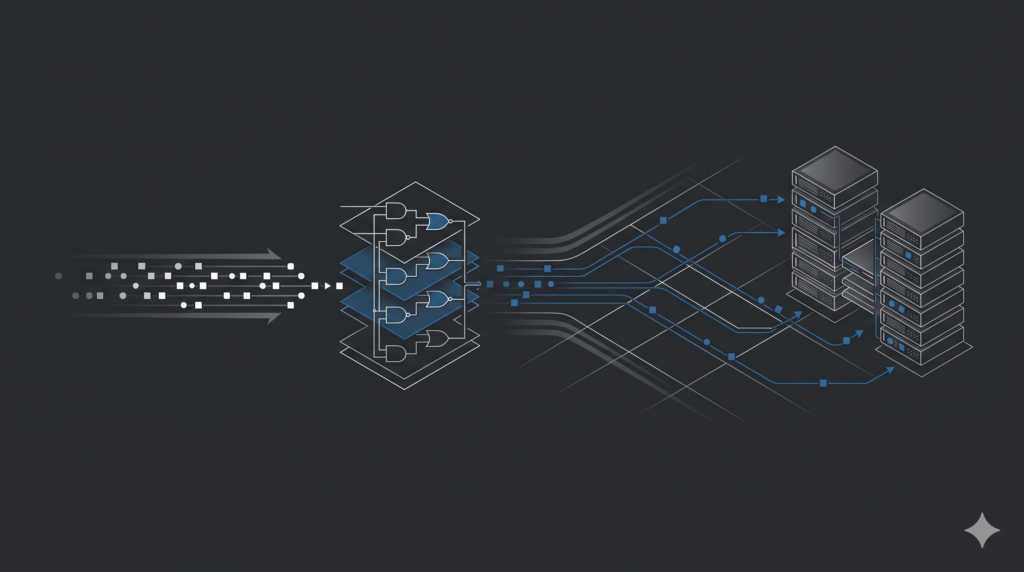
This physical separation creates an intense communication requirement. Engineers call this the All-to-All communication phase.
Every GPU must simultaneously exchange tokens with every other GPU in the cluster before the next mathematical step can occur. The system moves petabytes of information constantly to keep the experts fed.
WHY IT MATTERS NOW (THE HUMAN IMPACT)
This routing architecture dictates the financial profitability of hyperscale cloud providers. Compute is expensive, but idle compute burns capital without generating output.
When tens of thousands of GPUs train a massive sparse model, they generate immense network traffic. If the interconnects lack bandwidth, the GPUs simply stop and wait for data to arrive.
This waiting period destroys capital efficiency. A delayed token stalls an entire server rack. Operators pay thousands of dollars per hour for electricity and hardware leasing while the silicon sits completely idle.
Major hyperscale developers use this sparse design to control costs. The architecture reduces pure arithmetic load but shifts the absolute bottleneck to the networking layer. The constraint is no longer silicon processing speed, but the physical bandwidth of fiber-optic cables.
WHAT MOST PEOPLE MISS
The industry obsesses over sheer parameter counts. Analysts assume a one-trillion parameter model equals a trillion parameters of active computation.
The true reality involves extreme communication overhead. The gating network frequently suffers from load imbalance, routing too many tokens to a single popular expert.
This leaves the rest of the cluster starved for data. Fixing this requires complex capacity limits and token dropping algorithms, directly trading logic accuracy to prevent network collapse.
THE TRAJECTORY (12–36 MONTHS)
Over the next thirty-six months, data center architects will aggressively redesign cluster topologies to localize experts. Algorithms will intentionally place frequently paired experts onto the same physical silicon die or within the same server chassis.
This physical proximity completely bypasses the core network switch. It reduces the communication penalty by keeping data traffic strictly inside high-bandwidth copper connections like NVLink.
Simultaneously, silicon foundries will embed custom routing logic directly into the networking interface cards. This shifts the gating math off the primary GPU, allowing the network hardware to independently sort and dispatch tokens at the speed of light.
KEY TERMS
- Mixture of Experts (MoE): A machine learning architecture that divides a model into specialized sub-networks to increase capacity without proportionally increasing computational cost.
- Gating Network: A shallow neural network layer that decides which specific expert handles an incoming data token.
- All-to-All Communication: A collective network operation where every node in a cluster simultaneously sends and receives data from every other node.
- InfiniBand: A high-speed, low-latency computer networking standard heavily utilized in supercomputing and hyperscale AI clusters.
- Load Balancing: The algorithmic process of evenly distributing data tokens across all available experts to prevent processing bottlenecks.
SOURCES
- Google Research — Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Nvidia Technical Blog — Scaling Language Models with Mixture of Experts
- Microsoft DeepSpeed — DeepSpeed-MoE: Advancing Mixture-of-Experts Inference and Training to Trillions of Parameters
- Meta AI — FairScale: A general purpose modular PyTorch library for high performance and large scale training